KRaft简介
Kafka的共识机制KRaft,仍然处于预览机制。未来KRaft将作为Apache Kafka的内置共识机制将取代Zookeeper。该模式在2.8版本当中就已经发布了体验版本,在3.X系列中KRaft是一个稳定release版本。
KRaft运行模式的kafka集群,不会将元数据存储在zookeeper中,即部署新集群的时候,无需部署zk集群,因为Kafka将元数据存储在Controller节点的KRaft Quorum中。KRAFT可以带来很多好处,比如可以支持更多的分区,更快速的切换Controller,也可以避免Controller缓存的元数据和zk存储的数据不一致带来的一系列问题。
KRaft架构
首先来看一下KRaft在系统架构层面和之前的版本有什么区别。KRaft模式提出来去zookeeper后的kafka整体架构入下图是前后架构图对比:
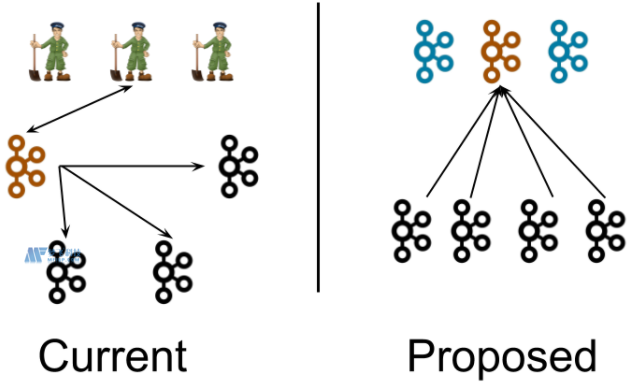
在当前架构中,一个kafka集群包含多个broker节点个一个ZooKeeper集群。我们在这张图中描绘了一个典型的集群结构:4个broker节点个3个ZooKeeper节点。kafka集群的Controller(橙色)在被选中后,会从ZooKeeper中加载他的状态。Controller指向其他Broker节点的箭头表示Controller在通知其他briker发生了变更,如Leaderanddisr和Updatemetdata请求。
在新的架构中,3个Controller节点代替三个ZooKeeper节点。控制器节点和Broker节点在不同的进程中。Controller节点中会选择一个成为Leader(橙色)。新架构中,控制器不会想Broker推送更新,而是Broker从这个Controller Leader拉取元数据的更新信息。
注意:尽管Controller进程在逻辑上与Broker进程是分离的,但他们不需要再物理上分离,即在某些情况下,部分所有Controller进程和Broker进程可以使同一个进程,即一个broker节点即是Broker也是Controller。另外在同一个节点上可以运行两个进程,一个是Controller进程,一个是broker进程,这相当于在较小的及群众。Zookeeper进程可以想Kafka Broker一样部署在相同的节点上。
部署
首先目前官方页面上并没有集群搭建文档。我们下载安装包,查看config/kraft下的README.md文件。可以看到详细说明。