






KRaft简介
Kafka的共识机制KRaft,仍然处于预览机制。未来KRaft将作为Apache Kafka的内置共识机制将取代Zookeeper。该模式在2.8版本当中就已经发布了体验版本,在3.X系列中KRaft是一个稳定release版本。
KRaft运行模式的kafka集群,不会将元数据存储在zookeeper中,即部署新集群的时候,无需部署zk集群,因为Kafka将元数据存储在Controller节点的KRaft Quorum中。KRAFT可以带来很多好处,比如可以支持更多的分区,更快速的切换Controller,也可以避免Controller缓存的元数据和zk存储的数据不一致带来的一系列问题。
KRaft架构
首先来看一下KRaft在系统架构层面和之前的版本有什么区别。KRaft模式提出来去zookeeper后的kafka整体架构入下图是前后架构图对比:
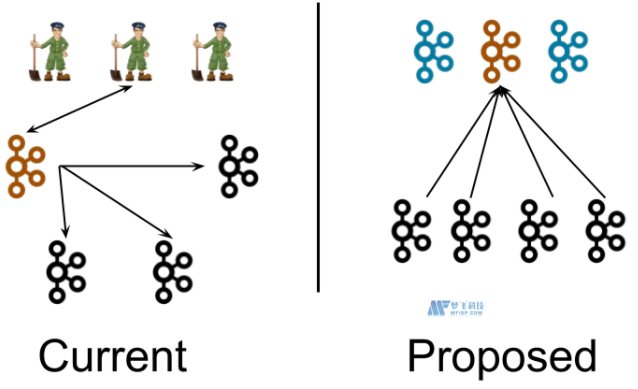
在当前架构中,一个kafka集群包含多个broker节点个一个ZooKeeper集群。我们在这张图中描绘了一个典型的集群结构:4个broker节点个3个ZooKeeper节点。kafka集群的Controller(橙色)在被选中后,会从ZooKeeper中加载他的状态。Controller指向其他Broker节点的箭头表示Controller在通知其他briker发生了变更,如Leaderanddisr和Updatemetdata请求。
在新的架构中,3个Controller节点代替三个ZooKeeper节点。控制器节点和Broker节点在不同的进程中。Controller节点中会选择一个成为Leader(橙色)。新架构中,控制器不会想Broker推送更新,而是Broker从这个Controller Leader拉取元数据的更新信息。
注意:尽管Controller进程在逻辑上与Broker进程是分离的,但他们不需要再物理上分离,即在某些情况下,部分所有Controller进程和Broker进程可以使同一个进程,即一个broker节点即是Broker也是Controller。另外在同一个节点上可以运行两个进程,一个是Controller进程,一个是broker进程,这相当于在较小的及群众。Zookeeper进程可以想Kafka Broker一样部署在相同的节点上。
部署
首先目前官方页面上并没有集群搭建文档。我们下载安装包,查看config/kraft下的README.md文件。可以看到详细说明。
根据说明,这里我搭建Kraft模式的kafka集群。这里我用的是3.1版本
这里我准备三台机器:
|
HOSTNAME |
IP |
OS |
|
node2 |
192.168.0.113 |
centos7.9 |
|
node3 |
192.168.0.114 |
centos7.9 |
|
node4 |
192.168.0.115 |
centos7.9 |
下载
官网下载
上传服务器并解压
这里我在node2机器上传到自己的目录下/home/guohao
cd /home/guohao
#解压
tar -zxvf kafka_2.13-3.1.0.tgz
cd /home/guohao/kafka_2.13-3.1.0/
配置server.properties
cd config/kraft/
vi server.properties
# 节点角色
process.roles=broker,controller
#节点ID,和节点所承担的角色想关联
node.id=1
# 集群地址
controller.quorum.voters=1@192.168.0.113:9093,2@192.168.0.114:9093,3@192.168.0.115:9093
#本机节点
listeners=PLAINTEXT://192.168.0.113:9092,CONTROLLER://192.168.0.113:9093
# 这里我修改了日志文件的路径,默认是在/tmp目录下的
log.dirs=/home/guohao/kafka_2.13-3.1.0/kraftlog/kraft-combined-logs
Process.Roles
每个Kafka服务器现在都有一个新的配置项,叫做Process.Roles, 这个参数可以有以下值:
- 如果Process.Roles = Broker, 服务器在KRaft模式中充当 Broker。
- 如果Process.Roles = Controller, 服务器在KRaft模式下充当 Controller。
- 如果Process.Roles = Broker,Controller,服务器在KRaft模式中同时充当 Broker 和Controller。
- 如果process.roles 没有设置。那么集群就假定是运行在ZooKeeper模式下。
如前所述,目前不能在不重新格式化目录的情况下在ZooKeeper模式和KRaft模式之间来回转换。同时充当Broker和Controller的节点称为“组合”节点。
对于简单的场景,组合节点更容易运行和部署,可以避免多进程运行时,JVM带来的相关的固定内存开销。关键的缺点是,控制器将较少地与系统的其余部分隔离。例如,如果代理上的活动导致内存不足,则服务器的控制器部分不会与该OOM条件隔离。
Quorum Voters
系统中的所有节点都必须设置 `controller.quorum.voters` 配置。这个配置标识有哪些节点是 Quorum 的投票者节点。所有想成为控制器的节点都需要包含在这个配置里面。这类似于在使用ZooKeeper时,使用ZooKeeper.connect配置时必须包含所有的ZooKeeper服务器。
然而,与ZooKeeper配置不同的是,`controller.quorum.voters` 配置需要包含每个节点的id。格式为: id1@host1:port1,id2@host2:port2。
分发并配置
cd /home/guohao
#解压
tar -zxvf kafka_2.13-3.1.0.tgz
cd /home/guohao/kafka_2.13-3.1.0/
#node3 server.properties
# 节点角色
process.roles=broker,controller
#节点ID,和节点所承担的角色想关联
node.id=2
# 集群地址
controller.quorum.voters=1@192.168.0.113:9093,2@192.168.0.114:9093,3@192.168.0.115:9093
#本机节点
listeners=PLAINTEXT://192.168.0.114:9092,CONTROLLER://192.168.0.114:9093
# 这里我修改了日志文件的路径,默认是在/tmp目录下的
log.dirs=/home/guohao/kafka_2.13-3.1.0/kraftlog/kraft-combined-logs
#node4 server.properties
# 节点角色
process.roles=broker,controller
#节点ID,和节点所承担的角色想关联
node.id=3
# 集群地址
controller.quorum.voters=1@192.168.0.113:9093,2@192.168.0.114:9093,3@192.168.0.115:9093
#本机节点
listeners=PLAINTEXT://192.168.0.115:9092,CONTROLLER://192.168.0.115:9093
# 这里我修改了日志文件的路径,默认是在/tmp目录下的
log.dirs=/home/guohao/kafka_2.13-3.1.0/kraftlog/kraft-combined-logs
运行KRaft集群
运行KRaft集群,主要分为三步:
- 用kafka-storage.sh 生成一个唯一的集群ID
./bin/kafka-storage.sh random-uuid
- #会生成一个uuid
- 用kafka-storage.sh 格式化存储数据的目录
-
#每个节点都要执行
-
#./bin/kafka-storage.sh format -t <uuid> -c ./config/kraft/server.properties
-
./bin/kafka-storage.sh format -t 04ofzeqFRgqBWQGtLEqmNQ -c ./config/kraft/server.properties
- 用bin/kafka-server-start.sh 启动Kafka Server
-
#每个节点都要执行
-
./bin/kafka-server-start.sh ./config/kraft/server.properties

运行KRaft集群
运行KRaft集群,主要分为三步:
- 用kafka-storage.sh 生成一个唯一的集群ID
./bin/kafka-storage.sh random-uuid
- #会生成一个uuid
- 用kafka-storage.sh 格式化存储数据的目录
-
#每个节点都要执行
-
#./bin/kafka-storage.sh format -t <uuid> -c ./config/kraft/server.properties
-
./bin/kafka-storage.sh format -t 04ofzeqFRgqBWQGtLEqmNQ -c ./config/kraft/server.properties
- 用bin/kafka-server-start.sh 启动Kafka Server
-
#每个节点都要执行
-
./bin/kafka-server-start.sh ./config/kraft/server.properties
实用工具
使用过程中,如果遇到问题,可能需要查看元数据日志。在KRaft中,有两个命令行工具需要特别关注下。kafka-dump-log.sh和kafka-metadata-shell.log。
KRaft模式下 ,原先保存在Zookeeper上的数据,全部转移到了一个内部的Topic:@metadata上了。比如Broker信息,Topic信息等等。所以我们需要有一个工具查看当前的数据内容。
Kafka-dump-log.sh是一个之前就有的工具,用来查看Topic的的文件内容。这工具加了一个参数--cluster-metadata-decoder用来,查看元数据日志,
平时我们用zk的时候,习惯了用zk命令行查看数据,简单快捷。bin目录下自带了kafka-metadata-shell.sh工具,可以允许你像zk一样方便的查看数据。
总结
Kafka 经常被认为是一个重量级的基础设施,管理Apache Zookeeper的复杂性就是这种看法存在的重要原因。而KRaft模式提供了一种很棒的、轻量级的方式来开始使用Kafka,或者可以使用它作为ActiveMQ或RabbitMQ等消息队列的替代方案。


