






数据湖屋是一种数据管理范式,将数据仓库和数据湖功能结合到统一平台,用于优化结构化和非结构化数据存储。虽然数据仓库长期以来一直是存储结构化数据的答案,但近几十年来数据的爆炸式增长导致数据湖存储了大量独特和非结构化数据类型。直到最近,领先的数据库软件和存储管理公司才开始开发和销售最新的混合解决方案,用于管理组织拥有的数据。

数据管道的演变:从仓库到数据湖
数据湖的发展源于企业组织和数据中心管理不断增加的数据量和不同类型数据方式的演变。
在了解数据湖之前,组织必须首先熟悉其前身:数据仓库和数据湖。
什么是数据仓库?
自 20 世纪 80 年代以来,数据仓库一直是专门用于存储用于报告和商业智能(BI) 的结构化数据的存储库。标准数据仓库接收通过提取、转换和加载(ETL) 软件过滤的外部和运营数据,该软件可高效地将结构化数据转换并存储在相同数据格式的存储库中。
什么是数据湖?
大约十年前,Pentaho 首席技术官 James Dixon 创造了“数据湖”一词来描述以原始格式存储数据的存储库。与存储结构化数据的数据仓库不同,数据湖包含各种结构化、半结构化和非结构化数据和类型。
虽然数据湖在许多企业用例中越来越受欢迎,但它最适合用于数据科学应用程序的验证。相比之下,其他数据湖内容则通过 ETL 解决方案传输,以用于数据仓库或实时数据库。
数据仓库和数据湖的问题
数据仓库问题:僵化和专有
由于数据仓库遵循严格的专有格式,因此它们无法支持新旧数据类型的混合,包括视频、音频、流媒体和深度学习模型,如人工智能 ( AI ) 和机器学习 ( ML )。
这种无法管理非结构化数据的情况迫使企业组织提取和存储多余的数据,以形成数据湖。
数据湖问题:疯狂且不可靠
尽管数据湖提供非结构化数据存储,但它却以不可靠的数据沼泽而闻名。相对于数据仓库的预期效率,数据湖往往表现不佳,难以支持 BI 应用程序。
同时使用数据仓库和数据湖:重复
自数据湖出现以来,组织一直试图通过两个不同的系统和团队来利用仓库和数据湖的功能。传统的 IT 专业人员和数据库管理员管理仓库,而数据科学家则专注于利用数据湖的潜力。
对于组织来说,数据仓库和数据湖的共存通常会导致数据重复、流程重复和成本增加。数据管理员解决这些问题的最新范例是数据湖屋。
什么是数据湖屋?
数据湖屋包含数据仓库和数据湖的组件,为管理员提供用于 BI、数据科学、深度学习和流分析的单一数据存储。借助数据湖屋,管理员可以使用类似于传统数据仓库管理的界面和数据治理来管理各种原始数据。
数据湖普遍接受的功能包括:
- 所有数据(结构化、半结构化和非结构化)都存储在一个存储库中
- 端到端流式传输,提供来自数据存储库的实时洞察
- 管理员可直接访问数据并执行读写操作
- 分离计算和存储,实现可扩展性和多用途
- 建立数据治理的架构支持
- 索引和数据压缩以提高查询速度
- 原子性、并发性、隔离性和持久性 (ACID) 事务支持
通过将多个系统(数据仓库和数据湖)整合到数据湖中,组织可以简化模式和数据治理的管理,并减少冗余、重复流程和管理成本。与云时代的数据湖一样,数据湖提供低成本存储和广泛的可扩展性。
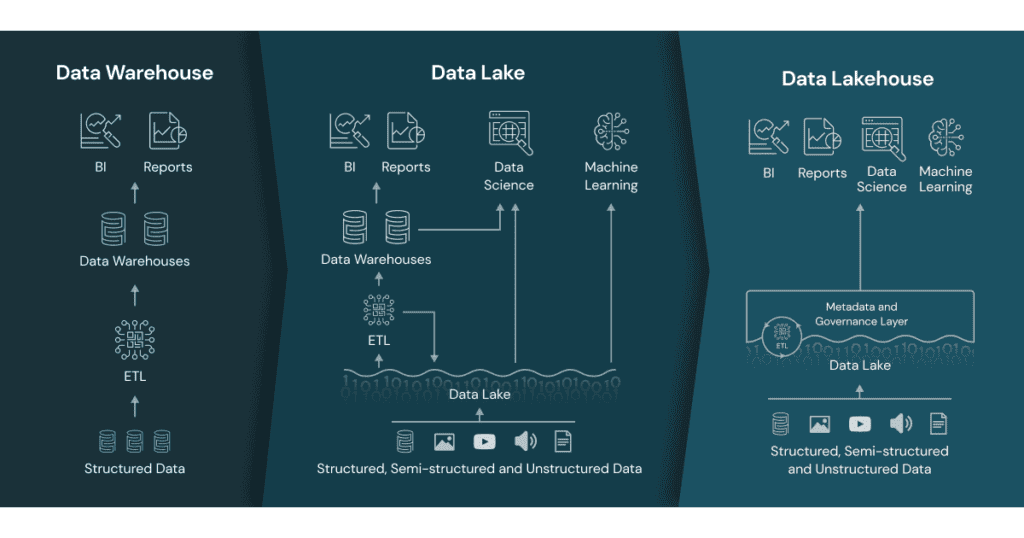
Databricks 的信息图展示了数据仓库、数据湖和数据湖屋之间的差异。

Data Lakehouse:两全其美
数据湖屋为组织的数据管理利益相关者之间的协作提供了桥梁。尽管这是一个较新的概念,但人们对管理结构化和非结构化数据的统一解决方案的希望仍然存在。在这个新兴市场中,几家知名供应商正在构建他们的数据湖屋功能。


